In this post, I’d like to introduce the upcoming major version of Knot Resolver project, which is currently in the testing and debugging phase, and we would greatly appreciate if you could try it out and give us any feedback on it.
![]()
Architecture
Knot Resolver is an open-source DNS resolver implementation, whose main distinguishing aspect is its modularity. Knot Resolver consists of several components: kresd (standalone resolving daemon), cache database with DNS records and cache garbage collector (a process that takes care of periodic cleaning of records in the cache). Furthermore, the resolving daemon is a single-threaded process, which means that it is very simple and straightforward, but in order to fully utilize the CPU resources, multiple separate instances of it need to be run. The number of instances usually corresponds to the number of CPU cores.
The core and additional functionalities of the resolver daemon are provided by modules that can be loaded or unloaded. This makes it possible to keep the resolver as lightweight as possible. Another unusual thing used to be the configuration, which was written in Lua, a full-fledged programming language. Together with the possibility of writing your own modules in C and/or Lua, this brings almost unlimited possibilities to extend or configure Knot Resolver and its functionalities.
There are several problems associated with the Knot Resolver’s architecture:
- Single-threaded processes do not allow for straightforward scalability on multi-core machines. Multiple processes have to be started, which then need to be taken care of individually. Systemd is usually used for this, but it cannot be deployed in Docker containers or some Linux distributions (e.g. Turris OS and OpenWrt).
- Individual modules must be loaded manually before use, otherwise their functions will not be available. For some modules, it is also necessary to ensure the correct load order.
- Configuration in Lua does not provide any way to validate its correctness before running in the resolver. In the best case, the error will show up immediately at startup, in the worst case, the resolver can run without a problem until the error shows up when faulty configuration or code is reached.
In the upcoming version, everything mentioned remains, but a new component called the manager is added, which tries to reduce the disadvantages of this modular architecture and improve user interaction with Knot Resolver.
The manager and process management
The manager is a new component written in Python that manages the rest of the resolver based on configuration:
- It instructs other processes to start or stop. For that, it uses supervisord, which also works in Docker containers and Linux distributions that do not support systemd. The manager makes it much easier to control Knot Resolver on systems without systemd.
- It uses a declarative configuration in the YAML format. Together with the sectioning, this makes the configuration much clearer and more readable. It is possible to validate the configuration even before starting the resolver. Internally, the manager will take care of loading or unloading the necessary modules in case of using their functions.
- It provides an HTTP API, which allows the configuration to be changed on the fly. The API also provides other useful functions such as obtaining aggregated metrics across all kresd processes.
There are two different control structures in Knot Resolver, see the following diagram. Semantically, the manager controls all the other parts of the resolver. However, instead of the manager, the root of the process tree is supervisord. It sits at the top of the process tree and controls all processes including the manager.
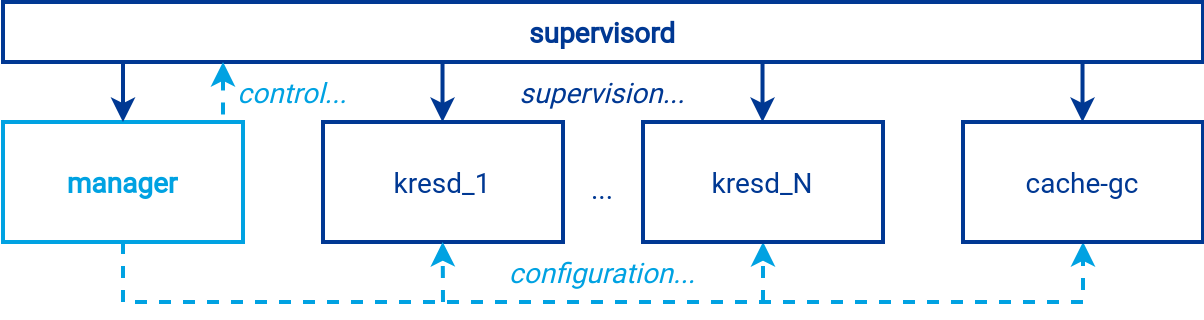
The process hierarchy slightly complicates the resolver startup procedure, which is noticeable when viewing the logs immediately after startup.
What happens during a cold start:
- The manager starts and loads the configuration from the file. If the configuration is valid, it will generate the configuration for supervisord.
- Supervisord is started using the exec system call, replacing the running manager process with the new supervisord process.
- Supervisord loads its configuration and starts a new manager instance. The newly started manager runs as a child process under supervisord, which is the desired state.
- The new manager loads the configuration from the YAML file and generates a Lua configuration for the other resolver processes based on it.
- Finally, the manager issues a command to supervisord to start the required number of processes, which then load the configuration created for them.
Because processes are controlled by supervisord, it is possible to resolve potential failures of individual processes without user intervention. Everything except supervisord automatically restarts upon failure. If the resolver cannot recover from a failure automatically, all the processes will stop and leave no garbage behind.
Configuration processing
The following diagram describes in more detail the process of loading the YAML configuration file during a cold start or when configuring the resolver at runtime using the HTTP API. For easier communication with the HTTP API, it is possible to use the kresctl CLI tool. The YAML configuration file is the only authoritative source of configuration, and unlike configuring via the API, it is persistent across restarts of the resolver or even the entire machine. A limitation of the HTTP API is also that it does not allow generating a configuration for supervisord – this can only be done on a cold start. Therefore, not everything that can be configured via the configuration file can be configured via the HTTP API.
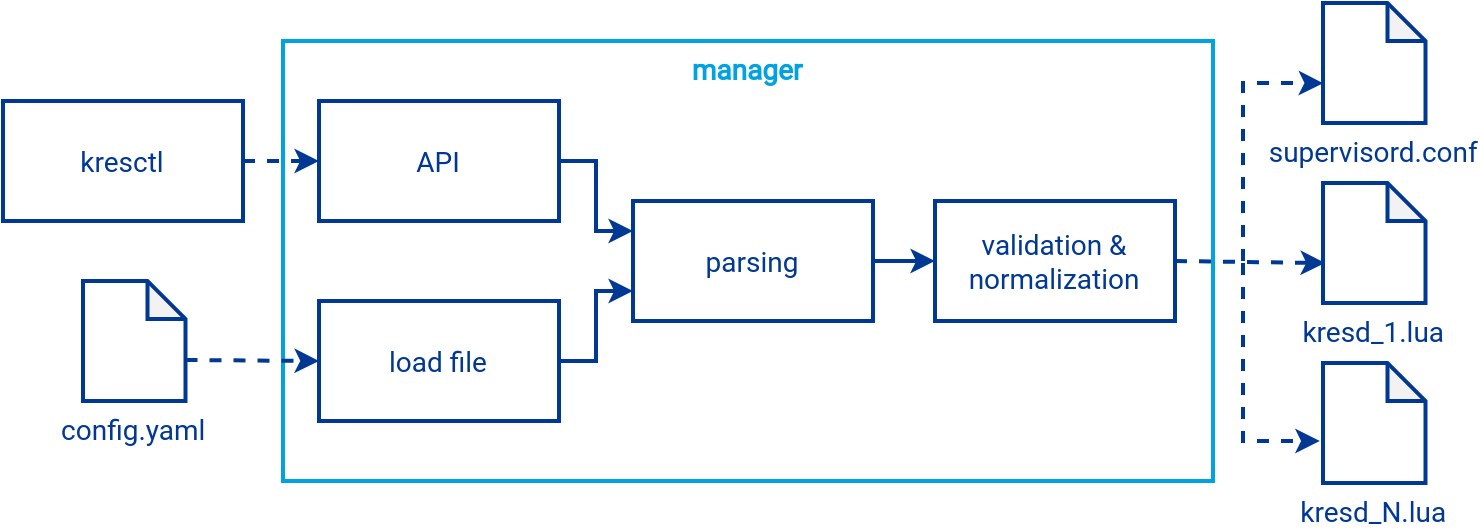
The configuration is loaded from a configuration file or received via the HTTP API. Then it is parsed from a YAML or JSON string into a uniform dictionary format.
Subsequently, the configuration data will be validated against the configuration schema and also normalized. For example, there will be the assignment of default values or values based on the context of the other configuration data. All this is possible thanks to the configuration schema layering. Transformations based on the context from the previous layer or retrieval of new values from the system are also possible. It creates the transformed configuration data that is validated against the next layer. The configuration structure that the user works with thus differs slightly from the one used internally by the resolver after validation and transformation.
After a successful validation, during a cold start, the configuration for supervisord is generated, otherwise only the configuration for the subprocesses will be created.
Installation
Complete documentation for the test version can be found at https://knot.pages.nic.cz/knot-resolver. How to install the test version for selected Linux distributions is described in the Getting Started chapter.
Startup
Our upstream packages for individual Linux distributions come with systemd integration by default. The difference in the new version is that it is no longer necessary to start individual instances of the kresd (kresd@1, kresd@2, …), but it is only needed to run the manager with the help of the new systemd service.
$ systemctl start knot-resolver # stop, reload, restart
The number of kresd processes that the manager is supposed to start is determined by numerical value in the configuration file under the configuration option workers. The value can also be set to auto which tells the manager to get the workers number automatically based on the number of CPU cores.
# /etc/knot-resolver/config.yaml
workers: 4
By default, Knot Resolver uses logging via systemd, which can be viewed using the systemd-journald service, for example, when the resolver fails to start.
$ journalctl -eu knot-resolver
Configuration
The new declarative configuration can be represented in YAML or JSON format (for HTTP API). It is possible to validate it before use to catch any errors before starting Knot Resolver.
Validation
Configuration validation always takes place automatically when the resolver is started. In case of incorrect configuration, the resolver startup will end with an error.
It is possible to validate the configuration without starting the resolver using CLI tool kresctl.
kresctl validate /etc/knot-resolver/config.yaml
If the validation fails, a detailed error message is shown with information on where and what is wrong. The same error message appears in the resolver log if configuration validation fails at startup.
Configuration validation errors detected:
[/network/listen[0]/port] value 65536 is higher than the maximum 65535
[/logging/level] degugg does not match any of the expected values (crit, ..., debug)
Dynamic configuration change
There are two ways to change Knot Resolver configuration at runtime. The resolver is able to dynamically change its own configuration by reloading the configuration file or via the HTTP API.
After editing the configuration file, just call the reload on systemd service.
$ systemctl reload knot-resolver
You can use kresctl utility to push the new configuration to the HTTP API.
To send a new configuration to the HTTP API, it is again possible kresctl tool or, for example, the standard curl tool.
$ kresctl config set /workers 8
In standard use, kresctl tool automatically reads the HTTP API configuration from the configuration file. Apart from configuration operations, it is possible to obtain resolver metrics or a complete JSON schema configuration via the HTTP API. Everything is described in more detail in the documentation of the management section.
The HTTP API is configured to listen on a unix socket by default. The HTTP API can also be configured to listen on a network interface and port.
# /etc/knot-resolver/config.yaml management: interface: 127.0.0.1@5000 # or use unix-socket instead of inteface # unix-socket: /my/new/socket.sock
A similar configuration change using the curl tool will look like this.
$ curl -H 'Content-Type: application/json' \ -X PUT -d '8' http://127.0.0.1:5000/v1/config/workers
Reconfiguration takes place as follows:
- The new configuration retrieved from a file or via the HTTP API is validated.
- The manager will check if there are no settings in the new configuration that would require a complete restart of the resolver including the manager and the creation of a new supervisord configuration. If the configuration changes cannot be performed on the fly, the operation ends with an error message and the configuration change needs to be performed by restarting the entire resolver using systemd service.
- The manager creates a new configuration for individual processes and with this configuration starts the so-called “canary” process, that helps to detect other possible errors before configuring individual processes.
- If everything works as it should in the “canary” process, the required number of processes with a new configuration is launched.
- The newly started processes replace the original ones already running at the given moment and because of that the reconfiguration is without service downtime.
Configuration examples
The first thing you’ll probably want to configure is the listening on network interfaces. The following snippet instructs the resolver to accept standard unencrypted DNS queries on localhost addresses. Secure DNS can be set up using DNS-over-TLS or DNS-over-HTTPS protocols. Setting a non-standard port for the protocol can be explicitly specified using the port parameter.
YAML also allows you to create variables (&interfaces) and then use it in other parts of the configuration (*interfaces). Thanks to this, there is no need to repeatedly list the network interfaces in the snippet.
# /etc/knot-resolver/config.yaml network: listen: # Unencrypted DNS on port 53 (default). - interface: &interfaces - 127.0.0.1 - "::1" # IPv6 addresses and other strings starting # with a colon need to be quoted. # DNS-over-TLS on port 853 (default). - interface: *interfaces kind: dot # DNS-over-HTTPS (port 443 is default). - interface: *interfaces kind: doh2 # The port can also be set explicitly. port: 5000
Another significant improvement not just in the configuration, but in the behavior of the resolver in general, is a change in the approach to the evaluation and application of policy rules. The declarative approach in the configuration ensures that the best matching rule for an incoming query is always selected. The old approach in previous versions selected the first rule that matched. It was therefore necessary to be very careful with the order of the rules, otherwise they often “overshadowed” each other in an unwanted way.
For user-identifying rules based on the source subnet, a smaller matching subnet will always take precedence over a larger one. This can be seen in the following example. One rule refuses users from all subnets, and other rules with smaller subnets allow them.
# /etc/knot-resolver/config.yaml views: # Allowed subnets. - subnets: [ 10.0.10.0/24, 127.0.0.1, "::1" ] answer: allow # A subnet for which additional rules # are assigned using tags. - subnets: [ 192.168.1.0/24 ] tags: [ malware, localnames ] # Everything else is refused. - subnets: [ 0.0.0.0/0, "::/0" ] answer: refused
Individual rules can be combined with each other. Tags are used for this, which you just have to assign to the rules that you want to combine. Combinations of different rules behave significantly more predictably than before. It is possible to filter users based on the subnet from which the query comes, and use the tag to assign additional query processing rules for this subnet. For example, these can be modifications in local DNS records, block lists and others.
# /etc/knot-resolver/config.yaml local-data: # A place for static DNS records. records: | www.google.com CNAME forcesafesearch.google.com rpz: # Malware block list. - file: /tmp/malware.rpz # It is only used for the "malware" tag. # For example, in combination with subnets in "views". tags: [ malware ]
# /etc/knot-resolver/config.yaml local-data: # Static pairs of domains and addresses. addresses: a1.example.com: 2001:db8::1 a2.example.org: - 192.0.2.2 - 192.0.2.3 - 2001:db8::4 # Import of "/etc/hosts" like format file. addresses-files: - /etc/hosts
The declarative approach also made it possible to cover more use cases around query forwarding. Forwarding to multiple targets is now possible even within a single query from a client. The target of a query may also be an authoritative server. Forwarding now does not break the CNAME and the resolver resolves the query properly.
# /etc/knot-resolver/config.yaml forward: # Forward all DNS queries to ODVR servers. - subtree: '.' servers: - address: - 2001:148f:fffe::1 - 193.17.47.1 # Communication is secured using TLS. transport: tls hostname: odvr.nic.cz
# /etc/knot-resolver/config.yaml forward: # Forward a query for internal domain. - subtree: internal.example.com servers: [ 10.0.0.53 ] options: # The target is the internal authoritative DNS server. authoritative: true dnssec: false
In conclusion
Finally, I would like to thank everyone who has tried or is about to try the new Knot Resolver. You can find more about the new version in the documentation. The best way to provide feedback is to use GitLab or send it to the project email address. If everything goes according to our plan, you can look forward to the first official release at the beginning of next year, marked as version 6.1.0.